Shrinkage Method: Subset
selection produces a model that is interpretable and has possibly lower prediction
error than the full model. However, because it is a discrete process variable
are either retained or discarded—it often exhibits high variance, and so
doesn’t reduce the prediction error of the full model. Shrinkage methods are
more continuous and don’t suffer as much from high variability.
Ridge
Regression: It is also known as Tikhonov
regularization. It is a regularized version of the linear regression. This forces
learning algorithms not only fit the data but also keep the model weights as
small as possible. The regularization term should be only added to the cost
function during training. Once the model is trained, you want to evaluate the
model’s performance using the unregularized performance measure. Ridge regression shrinks
the regression coefficients by imposing a penalty on their size. It minimizes
the penalized residual sum of squares,
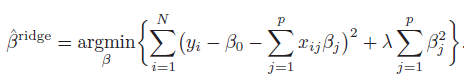
It can also be
written as

The equation shows that we
have applied constraints on the parameters. There is a one-
to-one
correspondence between the parameters λ in and t. When there are many correlated variables in a linear
regression model, their coefficients can become poorly determined and exhibit
high variance. A wildly large positive coefficient on one variable can be
canceled by a similarly large negative coefficient on its correlated cousin. By
imposing a size constraint on the coefficients, this problem is alleviated.
Writing the criterion
in matrix form,
RSS(
λ ) = (y - X β)T(y - X β) + λ βT β,
the ridge regression
solutions are easily seen to be

where I is the pxp identity matrix.








No comments:
Post a Comment
If you have any doubt, let me know